・0 pv・10 min read
二値分類モデルにおける混同行列の確認事項と練習問題

データサイエンティスト検定(DS検定)で出題される混同行列の問題について、学習用に整理した内容や、計算の慣れのために自作した練習問題を掲載する。
混同行列の基本事項
「画像に写っているのは犬かどうか?」「この患者はガンかそうでないか?」「試験に合格するか不合格か?」などのように「AかAでないか」を予測する機械学習モデルを二値分類モデルという。二値分類モデルの精度の評価として、判定が「正解か不正解か」の割合を計算するというのも一つの方法だが、混同行列として整理することで更に詳細な評価を行うことができる。
「AかAでないか」の判定結果はより詳細に、「本当はAだし予測もA」「本当はAでないが予測はA」「本当はAでないし予測もAでない」「本当はAだが予測はAでない」の4パターンに分けられる。Aであることを陽性(正例ともいう)、Aでないことを陰性(負例ともいう)とすれば、
真陽性(True Positive):実際は陽性で予測も陽性 → 正しく陽性と判定偽陽性(False Positive):実際は陰性で予測は陽性 → 誤って陽性と判定真陰性(True Negative):実際は陰性で予測も陰性 → 正しく陰性と判定偽陰性(False Negative):実際は陽性で予測は陰性 → 誤って陰性と判定というように表され、それぞれTP・FP・TN・FNと略して呼ばれる。二値分類の判定結果は必ずTP・FP・TN・FNのいずれかに分けられる。これを行列で整理したものが混同行列であり、次のようになる。

なお、「犬かどうか?」ではなく「犬か猫か猿か熊か?」といった判別を行う多値分類モデルについても結果を混同行列で表すことができるがここでは触れない。
このTP・FP・TN・FNを使って色々な評価指標を計算してモデルの精度を評価していく。計算自体は単なる割合の計算なので大したことないが、分母・分子になにを割り当てるのかを覚えるのが難しい(難しいはず…自分は最初訳が分からなかった)。
混同行列の計算が難しい所以は、
- まずTP・FP・FN・TNの区別が混乱する
- 評価指標がたくさん出てくる(和名と英名の対応も覚えないと…)
- 名前と意味・計算式のイメージを一致させにくい評価指標がある
からと考えている。
二値分類モデルの評価指標
正解率(Accuracy)
文字通り「全データに対して正しく予測できたデータはどれぐらいか?」を表す指標でこれは簡単分かりやすい。
全データはTP+FP+FN+TNで、正しく予測できたデータはTP+TNなので、以下のように計算する。
適合率(Precision)
「陽性と予測したデータのうち実際に陽性であるデータ」 の割合を表す指標。この辺りからもう名前と意味が一致しなくて嫌になってくる。
陽性と予測したデータというのは、「予測は陽性で実際も陽性(正しい) + 予測は陽性で実際は陰性(誤り)」 つまりTP+FPなので、以下のように計算する。
予測をベースに考え、「陽性と予測したものがどれだけ正しいのか?」という観点で評価したい場合に重視すべき指標である。
再現率(Recall)・特異度(Specificity)
まず再現率は、「実際は陽性であるデータのうち陽性と予測されたデータ」 の割合を表す指標。やはり名前と意味が一致しない。
実際は陽性であるデータというのは、「実際は陽性で予測も陽性(正しい) + 実際は陽性で予測は陰性(誤り)」 つまりTP+FNなので、次のように計算する。
実際をベースに考え、「本当に陽性のものをどれだけ正しく拾い上げられているか?」という観点で評価したい場合に重視すべき指標である。
次に特異度は、「実際は陰性であるデータのうち陰性と予測されたデータ」 の割合を表す指標で、つまり再現率の式を陰性に置き換えたものである。
実際は陰性であるデータというのは、「実際は陰性で予測も陰性(正しい) + 実際は陰性で予測は陽性(誤り)」 つまりTN+FPなので、次のように計算する。
真陽性率・偽陽性率
適合率・再現率に比べれば名前から意味をイメージしやすいと思う。
真陽性率は 「実際は陽性であるデータのうち正しく陽性と予測されたデータ」 の割合を表す指標であり、これは再現率と全く同じである。
偽陽性率は 「実際は陰性であるデータのうち誤って陽性と予測されたデータ」 の割合を表す指標であり、次のように計算する。
詳細は省くが、二値分類モデルの評価方法の1つにROC曲線というものがあり、それを作成する時にこの真陽性・偽陽性の考え方が必要になる。
F値
適合率と再現率は互いにトレードオフ(一方が上がればもう一方は下がる)の関係にあると言われている。
例えば、再現率重視で「陽性を一つも見落としたくないんだ!」と言うならば陽性判定の閾値を緩くすればいいが、そうすると陰性のものも陽性と誤判定する数が増えて適合率は下がる。
逆に、「陽性の判定は確実なほうがいいんだ!」というならば陽性判定の閾値を厳しくすればいいが、本当に陽性のものを拾えなくなる数が増えて再現率は下がる。
一般に、適合率と再現率の両方を同時に高めることは難しいとされている。
適合率と再現率のどちらを重視するかではなく両方をバランスよく使ってモデルの精度を評価するのがF値であり、適合率と再現率の調和平均を計算したものである。
調和平均とは各値の逆数の平均の逆数を取ったもので、つまり適合率をPと再現率をRとすると次のように計算する。
この値が1に近いほど精度の良いモデルと言える。
なお、上の式はF値の中のF1スコアと呼ばれるものであり、他にもF0.5やF2がある。
練習問題
混同行列に関する各評価値の計算や意味などを問う練習問題を作った(全て自作ですよ)。このような問題を4, 5問ぐらいやって慣れておけば、DS検定で出題されるレベルの混同行列の計算はもう完璧だと思う。
問題1
ある果物農家では、出荷ライン上の果物に傷があるかどうかをAIで判定する自動選別機の導入を検討している。
この自動選別機で1000個の果物を判定し、予測結果と正解を集計したところ以下の通りになった。ただし、「傷あり」を陽性としている。

この混同行列から正解率、適合率、再現率、特異度、真陽性率、偽陽性率、F値(F1)をそれぞれ求めよ。
問題2
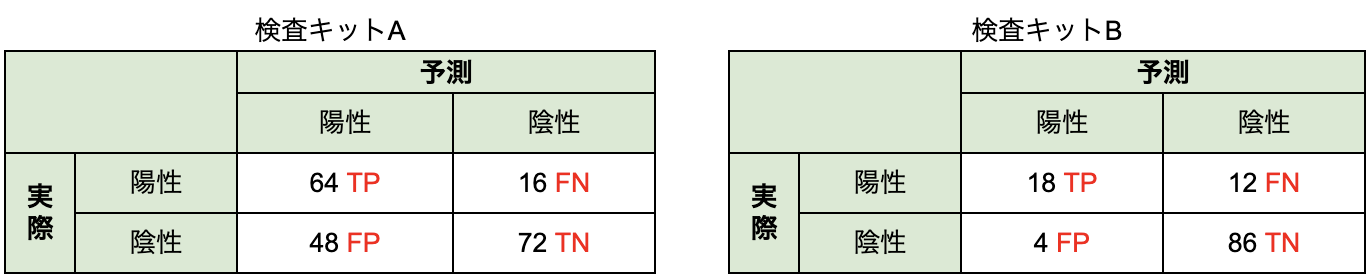
インフルエンザの検査キットAとBがある。患者を2つのグループに分けてA, Bそれぞれの検査キットで検査したところ、インフルエンザの陽性と陰性の判定結果は以下のようになった。

(1) 検査キットA, Bの適合率、再現率をそれぞれ求めよ。
(2) 以下の文章の空欄①, ②に「A」または「B」を入れよ。
医者からすればインフルエンザ患者をできるだけ見逃さない検査が望ましい。この観点から選ぶべき検査キットは[ ① ]である。一方、患者からすればインフルエンザだと判定された場合にその結果が正しい可能性が高い検査が望ましい。この観点から選ぶべき検査キットは[ ② ]である。
問題3
受信したメールが迷惑メールかどうかを判定し、迷惑フォルダか受信フォルダ(非迷惑メール)のいずれかに振り分けるフィルターを作成した。このフィルターを使って160件のメールを振り分けたところ、迷惑フォルダに入った迷惑メールが50件、迷惑フォルダに入った非迷惑メールが10件、受信フォルダに入った非迷惑メールが75件、受信フォルダに入った迷惑メールが25件であった。迷惑メールと判定した場合を正例として、以下の問に答えよ。
(1) 正解率、再現率、適合率を求めよ。
(2) 迷惑メール判定の閾値を厳しくして迷惑フォルダに入りにくくすると、再現率と適合率は元と比べて増加・減少のいずれになるか。ただし、閾値の変更による真陽性数と偽陽性数の減少率をそれぞれとした時、であるとする。
練習問題の答え
問題1の答え
与えられた混同行列から各指標を計算するだけである。
混同行列のどれがTP・FP・FN・TNに該当するかを落ち着いて区別してしまえば後は式に入れるだけ。

なお、混同行列のレコード数に極端な差があるデータを不均衡データといい、正解率を見ただけではモデルの性能を適切に評価できない場合がある。この問題のように陽性数と真陰性数に極端な差がある場合、正解率は0.91とかなり高精度に見える。しかし、再現率は0.65(約35%は傷ありを見落とす)だし、適合率は0.39(傷ありと判定したもののうち約60%は本当は傷がない)であるから、本当に精度が良いか微妙なところである。そこでF1の結果を見てみると0.5を割っており、実際にはあまり精度が良いとは言えない。
問題2の答え
(1)
これも与えられた混同行列でTP・FP・FN・TNを区別して計算するだけでいいが、問題1の混同行列とは予測と実際(正解)の位置が入れ替わっているので注意。予測と実際が入れ替わっているのはよくあるので、「適合率はヨコ!」「再現率はタテ!」のように覚えるのではなく、「適合率は予測をベースに計算」「再現率は実際をベースに計算」と意味を考えて覚えた方が良い。
検査キットA
問われてはいないがその他の指標も示しておく。
検査キットB
こちらもその他の指標も示しておく。
(2)
(1)の結果から、検査キットAは「適合率 < 再現率」で、検査キットBは「適合率 > 再現率」であることが分かった。
陽性である患者を見逃さないか?という観点で選ぶべきなのは再現率のほうが高いAであり、陽性判定が正しい可能性が高いか?という観点で選ぶべきなのは適合率のほうが高いBである。
したがって、 ①がAで②がB 。
問題3の答え
(1)
混同行列が与えられていないので、まずは問題文から値を読み取って自分で混同行列を作る必要がある。
この問題の場合は下記のようになる。

問われていないがその他の指標も示しておく。
(2)
迷惑フォルダに入りにくくなる、つまり迷惑メールと判定される数(陽性判定数)が減る傾向になるので、真陽性数TPと偽陽性数FPは共に減少する。
まず再現率だが、式はであり、分母のTP+FNは実際の陽性数そのものである。
つまり、TPが減れば同じ分だけFNが増える(逆もまた然り)のでTP+FNは常に一定値である。
したがって、は分子のTPが減少するだけなので、再現率は減少する。
次に適合率だが、問題文の「TPの減少率 < FPの減少率」という条件の下では、一般に適合率は増加する。
適合率の式は であり、分母・分子共に減少傾向になり比較しにくいので具体的な数値を入れてみたほうが分かりやすい。
となるように例えばとすると、閾値変更後の適合率は
であり、元の適合率0.83より増加する。
となるように例えばとすると、閾値変更後の適合率は
となるように例えばとすると、閾値変更後の適合率は
であり、元の適合率0.83より減少する。


